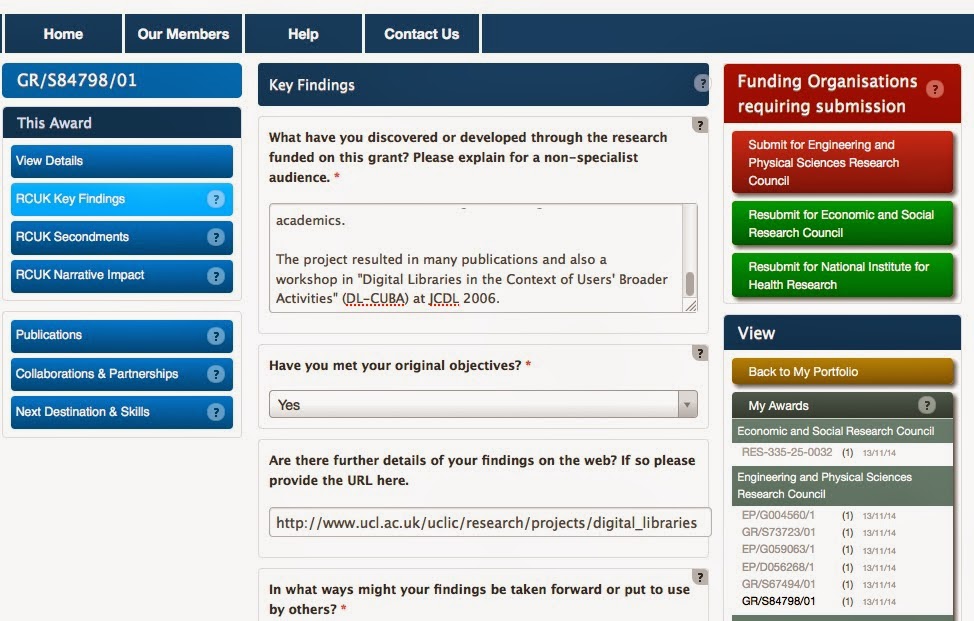
Two weeks ago, I summarised my own experience of using a research reporting system. I know (from subsequent communications) that many other researchers shared my pain. And Muki Haklay pointed me at another blog on usability of enterprise software, which discusses how widespread this kind of experience is with many different kinds of software system.
Today, I've had another experience that I think it's worth reporting briefly. I had a health screening appointment with a nurse (I'll call her Naomi, but that's not her real name). I had to wait 50 minutes beyond the appointment time before I was seen. Naomi was charming and apologetic: she was struggling with the new health record system, and every consultation was taking longer than scheduled. This was apparently only the second day that she had been using the health screening functions of the system. And she clearly thought that it was her own fault that she couldn't use it efficiently.
 She was shifting between different screen displays more times than I could count. She had a hand-written checklist of all the items that needed to be covered in the screening, and was using a separate note (see right) to keep track of the measurements that she was taking. She kept apologising that this was only because the system was unfamiliar, and she was sure she'd be able to work without the checklist before long. But actually, checklists are widely considered helpful in healthcare. She was working systematically, but this was in spite of the user interactions with the health record system, which provided no support whatsoever for her tasks, and seemed positively obstructive at times. As far as I know, all the information Naomi entered into my health record was accurate, but I left her struggling with the final item: even though, as far as either of us could see, she had completed all the fields in the last form correctly, the system wasn't letting her save it, blocking it with a claim that a field (unspecified) had not been completed. Naomi was about to seek help from a colleague as I left. I don't know what the record will eventually contain about my smoking habits!
She was shifting between different screen displays more times than I could count. She had a hand-written checklist of all the items that needed to be covered in the screening, and was using a separate note (see right) to keep track of the measurements that she was taking. She kept apologising that this was only because the system was unfamiliar, and she was sure she'd be able to work without the checklist before long. But actually, checklists are widely considered helpful in healthcare. She was working systematically, but this was in spite of the user interactions with the health record system, which provided no support whatsoever for her tasks, and seemed positively obstructive at times. As far as I know, all the information Naomi entered into my health record was accurate, but I left her struggling with the final item: even though, as far as either of us could see, she had completed all the fields in the last form correctly, the system wasn't letting her save it, blocking it with a claim that a field (unspecified) had not been completed. Naomi was about to seek help from a colleague as I left. I don't know what the record will eventually contain about my smoking habits!
This is just one small snapshot of users' experience with another system that is not fit for purpose. Things like this are happening in healthcare facilities all over the world every day of the week. The clinical staff are expected to improvise and act as the 'glue' between systems that have clearly been implemented with minimal awareness of how they will actually be used. This detracts from both the clinicians' and the patients' experiences, and if all the wasted time were costed it would probably come to billions of £/$/€/ currency-of-your-choice. Electronic health records clearly have the potential to offer many capabilities that paper records could not, but they could be so, so much better than they are if only they were designed with their users and purposes in mind.
Today, I've had another experience that I think it's worth reporting briefly. I had a health screening appointment with a nurse (I'll call her Naomi, but that's not her real name). I had to wait 50 minutes beyond the appointment time before I was seen. Naomi was charming and apologetic: she was struggling with the new health record system, and every consultation was taking longer than scheduled. This was apparently only the second day that she had been using the health screening functions of the system. And she clearly thought that it was her own fault that she couldn't use it efficiently.
She was shifting between different screen displays more times than I could count. She had a hand-written checklist of all the items that needed to be covered in the screening, and was using a separate note (see right) to keep track of the measurements that she was taking. She kept apologising that this was only because the system was unfamiliar, and she was sure she'd be able to work without the checklist before long. But actually, checklists are widely considered helpful in healthcare. She was working systematically, but this was in spite of the user interactions with the health record system, which provided no support whatsoever for her tasks, and seemed positively obstructive at times. As far as I know, all the information Naomi entered into my health record was accurate, but I left her struggling with the final item: even though, as far as either of us could see, she had completed all the fields in the last form correctly, the system wasn't letting her save it, blocking it with a claim that a field (unspecified) had not been completed. Naomi was about to seek help from a colleague as I left. I don't know what the record will eventually contain about my smoking habits!This is just one small snapshot of users' experience with another system that is not fit for purpose. Things like this are happening in healthcare facilities all over the world every day of the week. The clinical staff are expected to improvise and act as the 'glue' between systems that have clearly been implemented with minimal awareness of how they will actually be used. This detracts from both the clinicians' and the patients' experiences, and if all the wasted time were costed it would probably come to billions of £/$/€/ currency-of-your-choice. Electronic health records clearly have the potential to offer many capabilities that paper records could not, but they could be so, so much better than they are if only they were designed with their users and purposes in mind.